Google AdSense - horizontal Ad
🛑 The Day the Internet Stopped Talking: A Global Outage Hits Cloudflare
If you spent your day hitting refresh and yelling at your screen, you weren't alone. Today, Tuesday, November 18, 2025, the internet felt less like a global network and more like a massive, shared ghost town.
The cause? A major, ongoing internal technical failure at Cloudflare, the essential, yet often invisible, infrastructure company that handles the security and speed for millions of websites worldwide.
Starting in the morning hours (around 11:00 UTC), major platforms like X (Twitter), OpenAI's ChatGPT, Spotify, Canva, and countless others began flashing the dreaded "500 Internal Server Error." This wasn't a coordinated attack or a simple coding mistake; it was a systemic issue deep within the core routing of one of the internet's most critical gatekeepers.
This blog post provides a detailed analysis of what happened, the technical chain of events, and the uncomfortable lesson this event forces us to confront about the modern web.
The Outage Timeline: From Stability to Silence
The incident quickly escalated from scattered user reports to a full-blown global incident, officially recognized by Cloudflare engineers.
Incident Start: November 18, 2025 (Approx. 11:00 UTC)
Reports surged globally, particularly across the US, Europe, and parts of Asia. Users trying to access high-traffic sites were met with two primary, frustrating errors:
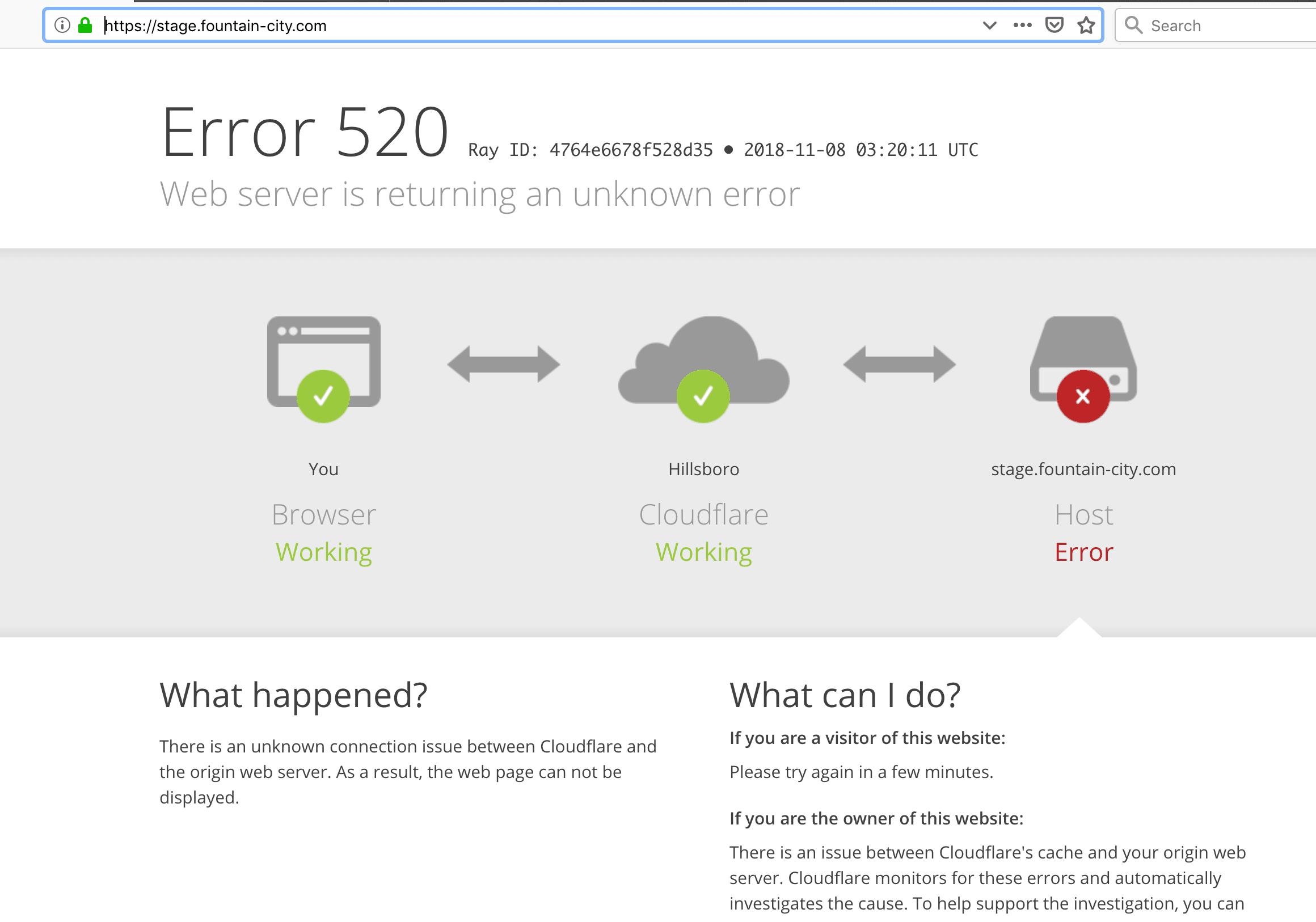
- The HTTP 500 Error: This generic "Internal Server Error" indicated that the server was aware of the problem but couldn't execute the request. Critically, these errors weren't coming from the websites themselves, but from Cloudflare's infrastructure layer sitting in front of them.
- Security Challenge Failures: Many users were stuck on Cloudflare's security or DDoS protection pages, seeing messages like, "Please unblock challenges.cloudflare.com to proceed," which then failed to load, effectively blocking access completely.
Cloudflare’s Response: Internal Degradation Confirmed
Cloudflare rapidly updated its status page, initially confirming they were "investigating an issue which impacts multiple customers" and noting the "Widespread 500 errors" and that even their own Dashboard and API were failing. The irony was palpable: engineers were struggling to manage the crisis using tools that were also affected by the crisis.
The most critical statement confirmed the nature of the problem: an internal service degradation.
The Possible Technical Cause: Maintenance and Traffic Spikes
While a full, post-mortem analysis will take weeks, the immediate technical details provided by Cloudflare suggest the failure originated from a complex systems operation:
- Scheduled Maintenance: Cloudflare’s status log showed maintenance scheduled for several key data centers on November 18 (including locations like Santiago). The critical risk during maintenance is traffic re-routing.
- Rerouting Failure/Traffic Spike: It is highly probable that during one of these complex re-routing procedures—or immediately after a maintenance window—an "unusual traffic spike" hit a crucial internal Cloudflare service.
- The Cascade Effect: This spike overloaded or confused a core component responsible for routing, security, or API functions. Because Cloudflare's network is deeply interconnected, this single failure rapidly cascaded, causing widespread HTTP errors across every connected data center, taking down everything in its path.
In simpler terms: one high-stakes procedure likely went wrong, creating a bottleneck that quickly choked the main arteries of Cloudflare's global network.
🤯 The Widespread Impact: Who Went Down?
Cloudflare is often referred to as "the biggest company you've never heard of" because of its essential, background role. The scale of the downtime today proved just how central they are to digital life.
The failure affected a massive, diverse array of services, proving that reliance on a single CDN or security provider is one of the biggest risks in the modern tech stack.
| Sector | Affected Services (Confirmed by Downdetector/Reports) | Impact Description | | :--- | :--- | :--- | | Social Media & Comms | X (Twitter), Discord, Grindr | Blank feeds, inability to post, severe loading failures. | | AI & Productivity | OpenAI (ChatGPT), Gemini, Perplexity, Canva, Dropbox | AI services unresponsive, creative and file hosting tools inaccessible. | | Financial & E-Commerce | Coinbase, Shopify, Moody's | Trading and checkout processes severely disrupted; critical financial reporting websites down. | | Gaming & Entertainment | League of Legends, Spotify, Letterboxd | Game servers inaccessible, music streaming failing. | | Government & Transit | NJ Transit, Electronic Visa Portals (e.g., for Saudi Arabia, Kenya) | Essential public services and travel applications paralyzed. | | Infrastructure Monitoring | Downdetector (Intermittently) | Even the site designed to tell you who is down was struggling because it relies on the very system that failed. |
The most chilling fact for any business is that if your site relied on Cloudflare, no amount of money, redundancy in your own code, or server power could save you from this external choke point.
🧠 The Uncomfortable Lesson: Centralization and Fragility
Every major cloud outage—whether it's AWS, Microsoft Azure, or now Cloudflare—teaches us the same painful lesson, and today's event reinforces it with global consequences: The internet is fragile because its infrastructure is centralized.
1. The Gatekeeper Problem
Cloudflare is a powerful gatekeeper. It manages DNS (telling browsers where to find a site), Content Delivery (caching files for speed), and DDoS mitigation (stopping attacks).
When a DNS entry, a cache, or a security check fails at the Cloudflare layer, the user never even reaches the website's main server. The problem is opaque and completely outside the site owner’s control.
2. The Maintenance Paradox
While it sounds strange that a scheduled procedure could cause an outage, this is often how the most complex systems fail. Engineers are working on live traffic, performing surgical changes (like rerouting data from one physical location to another). A bug in the code governing that maintenance, or an unexpected race condition triggered by the traffic shift, can send the entire network into a state of severe instability.
3. The Mandate for Multi-Cloud
For all services affected today, the business mandate going forward will be inescapable: You must implement multi-cloud or multi-CDN architecture.
This means ensuring that if Cloudflare (CDN 1) fails, your traffic automatically and instantly switches to a backup provider (CDN 2, such as Akamai or Fastly) with no user intervention. The cost of implementing this redundancy is always far less than the cost of losing an entire day of sales, service, and user trust.
Conclusion: Recovery and Reflection
As of the latest updates, Cloudflare's engineers have identified the issue and are actively deploying fixes. Services like Cloudflare Access and WARP are showing signs of recovery, a positive sign that the core network issue is being contained. However, full recovery will be a slow process, with error rates likely remaining high for hours as the network stabilizes.
The Cloudflare outage of November 18, 2025, will join the growing list of events that expose the risk inherent in modern web infrastructure. It’s a painful but necessary reminder that for all the decentralized ideals of the internet, the reality is that a few critical nodes hold the power.
The tiny trailing slash in our sitemap was frustrating, but today's issue proves that a single internal systems error at a company like Cloudflare can cause a multi-billion dollar headache for the global digital economy. The industry must prioritize resilient, distributed systems over monolithic dependency.
Current Status (As of Nov 18, 2025): Services are currently recovering. Cloudflare is managing remediation efforts, but expect intermittent access and higher error rates across major platforms.
Google AdSense - horizontal Ad